9.5. Eigenvalues and Eigenvectors#
import numpy as np
from numpy import linalg
9.5.1. Eigenvalues and Eigenvectors#
This section introduces eigenvalues and eigenvectors of a square matrix and explores some of their applications. The goal of this section is to dissect the action of linear maps into elements that are easy to visualize.
9.5.2. Motivation#
Consider a linear map \(T: \mathbb{R}^n\to \mathbb{R}^m\) defined by \(\vec{x} \mapsto A\vec{x}\). Although \(T\) moves \(\vec{x}\) in a variety of directions, there are some vectors on which the action of \(T\) is easy to understand. For example, suppose \(A = \begin{bmatrix} 3 & -2 \\ 1 & 0\\ \end{bmatrix}\), \(\vec{u } = \begin{bmatrix} 2 \\ 1 \end{bmatrix}\). Let’s compute \(A\vec{u}\)
A = np.array([[3,-2], [1,0]])
u = np.array([2,1])
A @ u
array([4, 2])
We can see that the image of \(\vec{u} = \begin{bmatrix} 2 \\ 1 \end{bmatrix}\) is
In fact, \(A\) streches \(\vec{u}\).
import matplotlib.pyplot as plt
def plot_map(vector, matrix):
x1 = vector[0]
y1 = vector[1]
x2 = (A @ vector)[0]
y2 = (A @ vector)[1]
ax = plt.axes()
ax.arrow(0, 0, x1, y1, head_width = 0.2,head_length = 0.2, fc ='b', ec ='b')
ax.arrow(0, 0, x2, y2, head_width = 0.2,head_length = 0.2, fc ='r', ec ='r')
ax.text(x1,y1 - 0.5,'$X$')
ax.text(x2,y2-0.5,'$AX$')
z = max(np.abs(x1), np.abs(x2), np.abs(y1),np.abs(y2))
ax.set_xticks(np.arange(-z-2, z+2, step = 1))
ax.set_yticks(np.arange(-z-2, z+2, step = 1))
ax.set_aspect('equal')
ax.set_xlabel("X")
ax.set_ylabel("Y")
plt.grid()
plt.show()
plot_map(u, A)
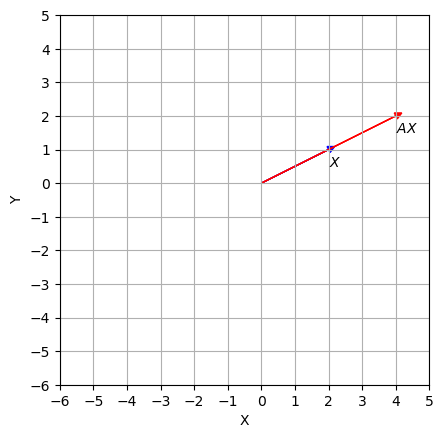
We are interested in such special vectors that when transformed by matrix \(A\), result in a scalar multiple of themselves. More generally, let \(A\) be an \(n\times n\) matrix. We seek non-trivial solutions to equations of the form:
If \(\vec{u}\neq 0\) is a solution for some \(\lambda\), we call \(\lambda\) an eigenvalue and \(\vec{u}\) an eigenvector of \(A\) corresponding to \(\lambda\).
Example 1
Consider the matrix equation:
Observe that \(\lambda = 2\) is an eigenvalue of \(A\) and \(\vec{u}\) is the corresponding eigenvector.
a. Is \(\vec{v} = \begin{bmatrix} 1 \\ -1 \end{bmatrix}\) also an eigenvector of \(A\)?
b. Is \(\lambda = 4\) an eigenvalue?
c. Show that \(\lambda = 1\) is an eigenvalue and find an eigenvector for it.
Solution:
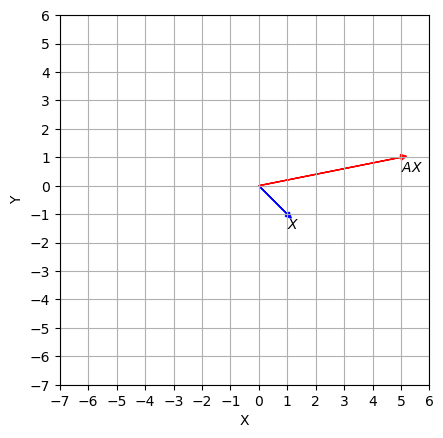
(a) Let’s compute \(A\vec{v}\):
v = np.array([1, -1])
A @ v
array([5, 1])
If there were a \(\lambda\) such that \(A\vec{v} = \lambda \vec{v}\), we would have obtained:
Which is not possible for any value of \(\lambda\), and as can be seen in the figure below, the vector \(\vec{v}\) does not satisfy the eigenvalue equation.
plot_map(v, A)
(b) No. \(\lambda = 4\) is a eigenvalue for \(A\) if and only if \(A\vec{x} = 4 \vec{x}\) has a non-trivial solution. Let’s reformulate this problem in terms of a homogenous equation which is easier to deal with:
The homogeneous equation \((A - 4 I_2) \vec{x} = 0\) has a non-trivial solution if and only if it has a free variable (a non-pivot column).
# identity matrix I_2
I_2 = np.eye(2)
A - 4*I_2
array([[-1., -2.],
[ 1., -4.]])
Clearly, the columns of \(A -4I\) are linearly independent; as a result, there is no free variable and the system has only the trivial solution \(\vec{x} = 0\).
(c) \(\lambda = 1\) is a eigenvalue for \(A\) if and only if \(A\vec{x} = 1 \vec{x}\) has a non-trivial solution.
A - I_2
array([[ 2., -2.],
[ 1., -1.]])
Since the columns of \((A - I_2)\) are linearly independent, there is a free variable and \(\lambda = 1\) is an eigenvalue of \(A\). To find a corresponding eigenvector \(\vec{u}\) we solve
Let’s set up the augmented matrix:
# the augmented vector
b = np.array([[0],[0]])
# add to the matrix
M = np.concatenate((A - I_2, b), axis = 1)
M
array([[ 2., -2., 0.],
[ 1., -1., 0.]])
Let’s recall the row operations:
def swap(matrix, row1, row2):
copy_matrix=np.copy(matrix).astype('float64')
copy_matrix[row1,:] = matrix[row2,:]
copy_matrix[row2,:] = matrix[row1,:]
return copy_matrix
# Replacing a row by the sum of itself and a multiple of another
def replace(matrix, row1, row2, scalar):
copy_matrix=np.copy(matrix).astype('float64')
copy_matrix[row1] = matrix[row1]+ scalar * matrix[row2]
return copy_matrix
M1 = swap(M, 0, 1)
M1
array([[ 1., -1., 0.],
[ 2., -2., 0.]])
M2 = replace(M1, 1, 0, -2)
M2
array([[ 1., -1., 0.],
[ 0., 0., 0.]])
A general solution for \((A - I_2)\vec{x} = 0\) is
and the set of all solutions is
each non-zero element of this set is an eigenvector corresponding to \(\lambda = 1\).
The above simple example leads to a general case:
Theorem 17
Let \(A\) be an \(n\times n\) matrix and \(\lambda\) be a scalar. The following statements are equivalent:
\(\lambda\) is an eigenvalue of \(A\).
\((A - \lambda I_n) \vec{x} = 0 \) has non-trivial solution.
\(det(A - \lambda I_n) = 0\)
9.5.3. Eigenspace and characteristic polynomial#
\(null(A - \lambda I_n)\) is a subspace of \(\mathbb{R}^n\) and contains the zero vector and all eigenvectors corresponding to \(\lambda\). This subspace is known as the eigenspace of \(A\) corresponding to \(\lambda\), and is denoted by \(E_{\lambda}\). Intuitively, a matrix acts as dilations on its eigenspaces.
Example 2
The set
Which we found in Example 1, is in fact the eigenspace \(E_1\) of \(A\) corresponding to \(\lambda =1\). And any vector \(\vec{u} \in E_1\) is preserved under the action of \(A\) (dilations factor = 1):
The polynomial \(P(\lambda) = \det(A - \lambda I_n)\) is called the characteristic polynomial of \(A\). The zeros of this polynomial are precisely the eigenvalues of \(A\). Thus, the polynomial can be factorized as:
For each \(\lambda_i\), where \(0 \leq i \leq k\), the power \(m_i\) is known as the algebraic multiplicity of \(\lambda_i\).
Example 3
Suppose
We will find all eigenvalues and their multiplicities of \(A\) by finding its characteristic polynomial.
Solution:
The characteristic polynomial is given by:
Expanding the determinant, we obtain the characteristic polynomial:
The zeros of this polynomial (the eigenvalues of \(A\)) are \(\lambda = 4\) with multiplicity \(1\), \(\lambda = 1\) with multiplicity \(1\), and \(\lambda = 8\) with multiplicity \(1\).
Example 4
Let \(A\) be the matrix given in Example 2. For each eigenvalue that we found in Example 2, find the corresponding eigenspace together with its dimension.
Solution:
The eigenspace corresponding to \(\lambda = 4\):
Therefore,
The eigenspace corresponding to \(\lambda = 1\):
Therefore,
The eigenspace corresponding to \(\lambda = 8\)
Therefore,
Before we move on to the next topic, let us check our calculation using numpy.linalg.eig from NumPy linear algebra:
A = np.array([[4, -1, 6], [0, 1, 6], [0, 0, 8]])
evalues , evectors = np.linalg.eig(A)
for i in range(evalues.shape[0]):
print(evalues[i], ' is an eigenvector with ', evectors[:,i], ' as the corresponding eigenvectors')
4.0 is an eigenvector with [1. 0. 0.] as the corresponding eigenvectors
1.0 is an eigenvector with [0.31622777 0.9486833 0. ] as the corresponding eigenvectors
8.0 is an eigenvector with [0.69853547 0.46569032 0.54330537] as the corresponding eigenvectors
Note that numpy.linalg.eig returns the unit vector of eigenvalues, and that is why we see different eigen vectors. To check that let’s normalize the eigenvector \(\begin{bmatrix} 9\\6\\7 \end{bmatrix}\) corresponding to \(\lambda = 8\):
v = np.array([9,6,7])
#normalizing v
e_v = v/np.linalg.norm(v)
e_v
array([0.69853547, 0.46569032, 0.54330537])
Let’s have another look at Example 2. The eigenvalues are the entries on the main diagonal. This is always true for triangular matrices and can be proved by induction:
Theorem 3
Let \(A\) be a square triangular matrix. Then the eigenvalues of \(A\) are the entries on the diagonal.
Numerical Notes
Example 3 provides a method for manually computing eigenvectors in simple cases. In practical situations, using matrix program and row reduction method to find an eigenspace (for a specified eigenvalue) may not be entirely reliable. Roundoff error can occasionally lead to a reduced echelon form with the wrong number of pivots. The best computer programs compute approximations for eigenvalues and eigenvectors simultaneously, to any desired degree of accuracy, for matrices that are not too large.
Some software such as Mathematica and Maple can use symbolic calculations to find the characteristic polynomial of a moderate-sized matrix. But there is no formula or finite algorithm to solve the characteristic equation of a general matrix \(n\times n\) for \(n\geq 5\). The best numerical methods for finding eigenvalues avoid the characteristic polynomial entirely. In fact, MATLAB finds the characteristic polynomial of a matrix \(A\) by first computing the eigenvalues \(\lambda_1, \lambda_2, \dots, \lambda_n\) of \(A\) and then expanding the product
Exercises#
Exercises
If \(\vec{v}\) is an eigenvector of \(A\) corresponding to \(\lambda\), what is \(A^3 \vec{v}\)?
If A is an \(n\times n\) matrix and \(2\) is an eigenvalue of \(A\), show that \(4\) is an eigenvalue of \(2A\).
If \(A\) is an invertible matrix with eigenvalue \(\lambda\) show that \(A^{-1}\) has eigenvalue \(1/\lambda.\)
Let
a. Find the eigenvalues of \(A\) and their multiplicities.
b. For each eigenvalue in part (a) find the corresponding eigenspace.
c. Find the dimension of each eigenspace in part (b) by finding a basis for it. How this result is related to your answer to part (a)?
9.5.4. Diagonalization#
This section introduces diagonalization and characterizes diagonalizability. Diagonalization is a useful factorization of a matrix \(A\) based on its eigenvalue–eigenvector information. This factorization allows us to quickly access properties that are invariant under similarity, such as rank, invertibility, and eigenvalues. It also enables us to calculate powers of \(A\) for large \(k\), which is a fundamental concept in various applications, including discrete dynamical systems.
Computing powers of a matrix#
Let’s consider the matrix \(A = \begin{bmatrix} 7 & 2\\ -4 & 1 \end{bmatrix}\). We wish to compute \(A^{k}\) for an arbitrary \(k\in \mathbb{N}\), given that \(A= PAP^{-1}\), where \(P = \begin{bmatrix} 1 & 1\\ -1 & -2 \end{bmatrix}\), and \(D = \begin{bmatrix} 5 & 0\\ 0 & 3 \end{bmatrix}\).
Using this decomposition, we have:
Since \(D\) is diagonal, \(D^{k} = \begin{bmatrix} 5^{k} & 0\\ 0 & 3^{k} \end{bmatrix}\). Additionally, \(P^{-1} = \begin{bmatrix} 2 & 1\\ -1 & -1 \end{bmatrix}\). Therefore,
This decomposition, known as diagonalization, enables us to compute \(A^k\) easily for large values of \(k\). Without such factorization, computing \(A^k\) for large matrices and large \(k\) can be a time-consuming task. Therefore, it is beneficial to find such decomposition before calculating the power of \(A\).
Unfortunately, this decomposition doesn’t exist for all matrices. The goal of this section is to characterize matrices that admit such a factorization.
Diagonalization#
An \(n \times n\) matrix \(A\) is called diagonalizable if it is similar to a diagonal matrix. More precisely, there exists an invertible \(n \times n\) matrix \(P\) and an \(n \times n\) diagonal matrix \(D\) such that \(A = PDP^{-1}\).
It turns out an \(n\times n\) matrix is diagonalizable if we can form a basis \(\mathbb{R}^n\) using eigenvectors of \(A\):
Theorem 18
An \(n \times n\) matrix \(A\) is diagonalizable if and only if \(A\) has \(n\) linearly independent eigenvectors.
In fact, suppose \(\lambda_1, \lambda_2, \dots, \lambda_n\) are eigenvalues of \(A\), and \(\{\vec{v_1}, \vec{v}_2, \dots, \vec{v}_n\}\) is the linearly independent set of eigenvectors of \(A\). If we form the matrix \(P\) by taking the eigenvectors as columns, and \(D\) is a diagonal matrix with eigenvalues \(\lambda_1, \lambda_2, \dots, \lambda_n\) on the diagonal, then we have \(A = PDP^{-1}\).
Finding eigenvectors in general is not an easy task, and is not clear how to check which \(n \times n\) matrices have \(n\) linearly independent eigenvectors. The next theorem partially addresses this issue.
Theorem 19
The eigenvectors corresponding to distinct eigenvalues are linearly independent.
Combining Theorem 18 and Theorem 19, we obtain the following corollary:
Corollary 1
An \(n \times n\) matrix with \(n\) distinct eigenvalues is diagonalizable.
Example 1
Is
diagonalizable? If yes find a diagonalization for it.
Solution
To determine if \(A\) is diagonalizable we need to find eigenvalues and to check if it admits \(3\) linearly independent eigenvectors.
Step 1
we use linalg.eigvas to find the eigenvalues and eigenvectors of \(A\):
A = np.array([[1,3,3],[-3,-5,3],[3,3,1]])
# find evalues and evectors
evalues, evectors = linalg.eig(A)
print("eigenvalues = ", evalues)
eigenvalues = [-5. -2. 4.]
\(A\) has three distinct eigenvalues and therefore it is diagonalizable by Corollary 1.
Step 2: Constructing the diagonal matrix \(D\)
lambda_1 = evalues[0]
lambda_2 = evalues[1]
lambda_3 = evalues[2]
D = np.array([[lambda_1, 0, 0], [0, lambda_2, 0], [0, 0, lambda_3]])
D
array([[-5., 0., 0.],
[ 0., -2., 0.],
[ 0., 0., 4.]])
Step 3 : Finding the matrix \(P\) whose \(i\)th column is an eigenvector corresponding to \(\lambda_{i}\) for \(i\in \{1,\ 2,\ 3\}\):
# set up the invirtible matrix P
P = evectors
Step 4: compute the inverse of matrix P
# compute the inverse of P
Q = linalg.inv(P)
Step 5 (sanity check): Now that we have \(D\), \(P\), \(Q = P^{-1}\), lets check if \(A = PDQ\)
P @ D @ Q
array([[ 1., 3., 3.],
[-3., -5., 3.],
[ 3., 3., 1.]])
Example 2
Is
diagonalizable? If yes find a diagonalization for it.
Solution:
Step 1: Finding eigenvalues and eigenvectors of \(A\):
A = np.array([[1,3,3],[-3,-5,-3],[3,3,1]])
# find evalues and evectors
evalues, evectors = linalg.eig(A)
print("eigenvalues = ", evalues)
eigenvalues = [ 1. -2. -2.]
\(A\) has 2 eigenvalues: \(\lambda_1 = 1\) with multiplicity 1 and \(\lambda_2 = -2\) with multiplicity 2. Note that we cannot use Corollary 1 anymore because eigenvalues are not distinct. To check if \(A\) is diagonalizable, we need to find three linearly independent eigenvectors of \(A\). Lets have a look at our eigenvectors:
# A matrix whose columns are eigenvectors:
P = evectors
# computes the rank of P
np.linalg.matrix_rank(P)
3
Since \(rank(P) = 3\) the columns of \(P\) are linearly independents. Thus, \(A\) is diagonalizable by Theorem 1.
Step 2: Finding the diagonal matrix \(D\)
lambda_1 = evalues[0]
lambda_2 = evalues[1]
lambda_3 = evalues[2]
D = np.array([[lambda_1, 0, 0], [0, lambda_2, 0], [0, 0, lambda_3]])
D
array([[ 1., 0., 0.],
[ 0., -2., 0.],
[ 0., 0., -2.]])
Step 3: Finding the matrix \(P\) whose \(i\)th column is an eigenvector corresponding to \(\lambda_{i}\) for \(i\in \{1,\ 2,\ 3\}\). We already have this matrix so we go to the next step.
Step 4: Computing the inverse of \(P\)
# computing the inverse of P
Q = np.linalg.inv(P)
Q
array([[-1.73205081, -1.73205081, -1.73205081],
[ 0.89919543, 2.75763333, 1.8584379 ],
[-0.6541932 , 0.5254512 , 1.1796444 ]])
Step 5 (sanity check): lets check if \(A = PDQ\)
# check A = PDQ
P @ D @ Q
array([[ 1., 3., 3.],
[-3., -5., -3.],
[ 3., 3., 1.]])
The next theorem provides another way to characterize the diagonalizability of matrices based on the multiplicity of eigenvalues. Before stating the theorem, we need the following definition:
Suppose \(A\) is a square matrix and \(\lambda\) is an eigenvalue of \(A\). The dimension of the corresponding eigenspace \(E_{\lambda} = null(A -\lambda I)\) is called the geometric multiplicity of \(\lambda\).
Theorem 20
A square matrix \(A\) is diagonalizable if and only if the algebraic multiplicity of each eigenvalue is equal to its geometric multiplicity. More formally, if \(\lambda_1, \lambda_2, \dots, \lambda_p\) are eigenvalues of \(A\) with algebraic multiplicities \(m_1, m_2, \dots, m_p\), respectively, then
Recall that dim(\(E_{\lambda_i}\)) = dim null\((A-\lambda_i I)\) = the number of non-pivot columns in \((A-\lambda_{i} I)\)
Example 3
Is \( M = \begin{bmatrix} 1 & 1 & 0 \\ 0 & 1 & 1 \\ 0 & 0 & 2 \end{bmatrix} \)
diagonalizable? If so, find a diagonalization for it.
Solution:
\(M\) is an upper triangular matrix, and its eigenvalues are on the diagonal: \(\lambda_1 = 1\) with algebraic multiplicity 2 and \(\lambda_2 = 2\) with algebraic multiplicity 1.
Since we don’t have distinct eigenvalues, Corollary 1 doesn’t apply here. Let’s take a look at our eigenvectors:
import numpy as np
from numpy import linalg
M = np.array([[1, 1, 0], [0, 1, 1], [0, 0, 2]])
evalues, evectors = np.linalg.eig(M)
p = evectors
np.linalg.matrix_rank(p)
2
Observe that the rank of matrix \(P\) is two, which means we don’t have three linearly independent eigenvectors in \(M\). However, using Theorem 3, we can confirm that this is not the case, and consequently, \(M\) is not diagonalizable. In fact, it is straightforward to check that the geometric multiplicity of \(\lambda = 1\) is 1 (\(\text{dim}(E_1) = 1\)), while the algebraic multiplicity is 2. Thus, \(M\) is not diagonalizable.
Diagonalization as a change of basis#
Recall that similar matrices represent the same linear map under two different choices of a pair of bases for \(\mathbb{R}^n\) and \(\mathbb{R}^m\). More precisely, suppose \(A = PCP^{-1}\) (\(C\) is not necessarily diagonal), then the matrix representation of \(T\) with respect to the basis \(B\) (formed by the columns of \(P\)) is \(C\). Conversely, changing the basis of \(\mathbb{R}^n\) leads to a matrix representation of \(T\) that is similar to \(A\) (section 3.4). This particularly applies to diagonalizable matrices because a matrix is diagonalizable if it is similar to a diagonal matrix.
Theorem 20 (Diagonal Matrix Representation)
Suppose \(T: \mathbb{R}^n \to \mathbb{R}^n\) and \(A\) is the standard matrix representation of \(T\) that is diagonalizable. Let \(A = PDP^{-1}\) be a diagonalization of \(A\) where \(D\) is an \(n\times n\) diagonal matrix, and \(P\) is an invertible \(n\times n\) matrix. If \(B\) is the basis for \(\mathbb{R}^n\) formed by the columns of \(P\), then \(D\) is the matrix representation of the transformation \(T: (\mathbb{R}^n, B) \to (\mathbb{R}^n, B)\).
Example 3 Let \(T: \mathbb{R}^2 \to \mathbb{R}^2\) and
be the standard matrix representation of \(T\). Find a basis \(B\) for \(T\) such that the matrix representation of \(T\) with respect to \(B\) is diagonal.
Solution:
From Example 1, we know that \(A = PAP^{-1}\) where \(P = \begin{bmatrix} 1 & 1 \\ -1 & -2 \end{bmatrix}\) and \(D = \begin{bmatrix} 5 & 0 \\ 0 & 3 \end{bmatrix}\).
The columns of \(P\) are eigenvectors of \(A\), and they form a basis \(B\) for \(\mathbb{R}^2\). By Theorem 2, \(D\) is the matrix representation of \(T\) with respect to \(B\). In fact, the mappings \(\vec{x} \to A\vec{x}\) and \(\vec{x} \to D\vec{x}\) describe the same linear transformation, relative to different bases.
Exercises#
Suppose
a. Is M diagonalizable? If yes find a diagonalization for it.
b. Use this diagonalization to compute \(M^{100}\)
Suppose
Is \(C\) diagonalizable?
Let \(A\) be a \(5\times 5\) matrix, with two eigenvalues. One eigenspace is three-dimensional, and the other is two-dimensional. Is \(A\) diagonalizable?
Compute \(A^{200}\) where
9.5.5. Discrete Dynamical Systems#
In this section, we will explore the application of diagonalization to discrete dynamical systems, focusing on their long-term behavior.
Modeling Dynamical Systems as sequence of linear systems#
In many fields (e.g., ecology, biology, economics, etc.), we wish to mathematically model and study a dynamic system that changes over time. We are usually given several features of the system that are measured at (discrete) different time intervals which can be viewed as a sequence of vectors
We interpret \(\vec{x_i}\) as the state of a system at time \(t = i\). We also assume that there is a matrix \(A\) such that
Our goal is to develop a formula for \(x_n\) and describe what can happen when \(n\) approaches to infinity.
Let’s consider the movement of populations or groups of people from one region to another. We want a simple model that considers the changes in the population of a city and its surrounding suburbs over a period of years. Let’s say the initial year is 2020 and denote the population of the city and suburbs by \(c_0\) and \(s_0\), respectively. Now we can form the initial vector population \(\vec{x_0} = \begin{bmatrix} c_0\\ r_0\\ \end{bmatrix}\). Similarly, for 2021 and subsequent years, denote the populations of the city and suburbs by the vectors
How can be these vectors mathematically related?
Suppose demographic studies show that each year about \(5\%\) of the city’s population moves to the suburbs (and \(95\%\) remains in the city), while \(3\%\) of the suburban population moves to the city (and \(97\%\) remains in the suburbs). With this information, we can find the vector population \(\vec{x_1}\) based on the initial population \(\vec{x_0}\). After the first year, \(c_0 95\%\) remain in the city and \(c_0 0.05\) move to the suburbs. Additionally, \(s_0.97\%\) remain in the suburbs and \(s_0 0.03\) move to the city. Therefore,
The matrix \(M = \begin{bmatrix} 0.95 & 0.03 \\ 0.97 & 0.05 \\ \end{bmatrix}\) is called the migration matrix. Consequently, we can write
and the sequence
describes the population of the city/suburbs over a period of years.
Example 1
Compute the population of the region just described for the years 2021 and 2022, given that the initial population in 2020 was \(600,000\) in the city and \(40,000\) in the suburbs.
Solution:
import numpy as np
# migration matrix
M = np.array([[0.95, 0.03] ,[0.05, 0.097]])
# initial population vector x_0
x_0 = np.array([600000, 40000])
# population vector x_1
x_1 = M @ x_0
print('the population of city in 2021 was = ', x_1[0],'\n')
print('the population of suburbs in 2021 was = ', x_1[1], '\n\n')
# population vector x_2
x_2 = M @ x_1
print('the population of the city in 2022 was = ', x_2[0],'\n')
print('the population of suburbs in 2022 was = ', x_1[1], '\n\n')
the population of city in 2021 was = 571200.0
the population of suburbs in 2021 was = 33880.0
the population of the city in 2022 was = 543656.4
the population of suburbs in 2022 was = 33880.0
Long-term behavior of dynamical systems#
Eigenvalues and eigenvectors can be used to understand the long-term behavior or evolution of a dynamical system described by an equation in the form of \(\vec{x}_{k+1} = A \vec{x}_{k}\). We assume that \(A\) is diagonalizable with \(n\) linearly independent eigenvectors \(\{\vec{v_1}, \vec{v}_2, \dots, \vec{v}_n\}\) and corresponding eigenvalues \(\lambda_1, \lambda_2, \dots, \lambda_n\). For convenience, let’s assume the eigenvectors are arranged such that \(|\lambda_1| \geq |\lambda_2| \geq \dots \geq |\lambda_n|\). Since \(\{\vec{v_1}, \vec{v}_2, \dots, \vec{v}_n\}\) forms a basis for \(\mathbb{R}^n\), any initial vector \(\vec{x}_0\) can be expressed uniquely as:
By applying \(A\) to both sides, we have:
And in general:
The above equation represents the evolution of the system over time. It shows that each component of the vector \(\vec{x}_k\) is a linear combination of the eigenvectors \(\vec{v_i}\), scaled by the corresponding eigenvalues \(\lambda_i\) raised to the power of \(k\).
As an example, let’s consider a predator-prey system involving owls and wood rats. The population vectors \(\vec{x}_k\) at time \(k\) are given by:
where \(O_k\) is the population of owls and \(R_k\) is the population of rats (measured in thousands). The populations evolve according to the following equations:
Here, the coefficient \(0.5\) in the first equation says that, without wood rats for food, only half of the owls will survive each month. The coefficient \(1.1\) in the second equation says that, in the absence of owls as predators, the rat population will grow by 10% each month. The parameter \(p\) is a positive value to be specified.
To determine the evolution of this system, we can compute the eigenvalues and eigenvectors of the coefficient matrix \(A\), and then apply equation \((**)\). For \(p = 0.104\), lets find the evolution of this system:
# coefficient matrix
A = np.array([[0.5, 0.4],[-0.104, 1.1]])
# Computing the eigenvalues and eigenvectors of A
np.linalg.eigvals(A)
array([0.58, 1.02])
Note that \(|\lambda_1| \leq 1\) and \(|\lambda_2| \geq 1\). A straightforward calculation shows that the corresponding eigenvectors are \(\vec{v_1} = \begin{bmatrix} 5\\1 \end{bmatrix}\) and \(\vec{v_2} = \begin{bmatrix}10 \\ 13 \end{bmatrix}\), respectively. The initial vector \(\vec{x_0}\) can be expressed as a linear combination of the eigenvectors:
Therefore, according to equation \((**)\), we have:
As \(k \to \infty\), the term \((\lambda_1)^{k} \vec{v_1}\) approaches zero, allowing us to approximate:
Furthermore, observe that:
The above approximation shows that both the number of owls and rats grow by an approximate factor of 1.02 each month.
let’s calculate some population vectors, assuming the initial population vector is \(\begin{bmatrix} 10\\20 \end{bmatrix}\).
import numpy as np
# A matrix whose columns are eigenvectors
evectors = np.array([[5, 10], [1, 13]])
# Initial vector
x_0 = np.array([1, 2])
# Solving the equation for d_1 and d_2
d = np.linalg.solve(evectors, x_0)
# Extracting d_2
d_2 = d[1]
# Eigenvalues corresponding to the eigenvectors
evalues = np.array([10, 20]) # Replace with the actual eigenvalues
# Iterating over the range
for k in range(10):
# Calculating the population using the eigenvalues, eigenvectors, and d_2
population = d_2 * pow(evalues[1], k+1) * evectors[1]
print('At month', k+1, 'the owl population is', population[0],' and ', 'the rat population is', population[1],'\n')
At month 1 the owl population is 3.2727272727272725 and the rat population is 42.54545454545454
At month 2 the owl population is 65.45454545454545 and the rat population is 850.9090909090909
At month 3 the owl population is 1309.090909090909 and the rat population is 17018.181818181816
At month 4 the owl population is 26181.81818181818 and the rat population is 340363.63636363635
At month 5 the owl population is 523636.36363636365 and the rat population is 6807272.7272727275
At month 6 the owl population is 10472727.272727273 and the rat population is 136145454.54545456
At month 7 the owl population is 209454545.45454547 and the rat population is 2722909090.909091
At month 8 the owl population is -27786072.436363637 and the rat population is -361218941.6727273
At month 9 the owl population is 147091381.52727273 and the rat population is 1912187959.8545456
At month 10 the owl population is 130576309.52727273 and the rat population is 1697492023.8545456
Note that if the absolute values of both eigenvalues are less than 1, then both populations will tend towards zero for large values of \(k\). If \(\lambda_1 = 1\) and \(\lambda2 < 1\), then
Finally, if \(\lambda_1 = 1\) and \(\lambda2 \geq 1\), then
Exercise#
Exercises
Let \(A\) be a \(2\times 2\) matrix with eigenvalues \(5\) and \(\frac{1}{5}\) and corresponding eigenvectors
Let \(\vec{x}_k\) be a solution of \(\vec{x}_{k+1} = A \vec{x}_{k}\), \(\vec{x}_0 = \begin{bmatrix} 9 \\ 1 \end{bmatrix}\) .
a. Compute \(\vec{x}_1 = A\vec{x}_0\)
b. Find a formula for \(\vec{x}_k\) involving \(k\) and the eigenvectors of \(A\).
c. Describe what happens when \(k\to \infty\).