Show code cell source
# import libraries
# Always run this cell first!
import numpy as np
import pandas as pd
import scipy.stats as stats
from scipy.stats import powerlaw
from scipy import integrate
from scipy.integrate import odeint
import math
import random
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.colors import cnames
from matplotlib import animation
import scipy
import statsmodels.api # appear to need to import the api as well as the library itself for the interpreter to find the modules
import statsmodels as sm
from matplotlib import ticker
import seaborn as sns
import plotly.graph_objects as go
import plotly.offline
plotly.offline.init_notebook_mode(connected=True) # make plotly work with Jupyter Notebook using CDN
from scipy.stats import linregress
import folium
from folium.plugins import MarkerCluster
# an extra function for plotting a straight line
def plot_abline(slope, intercept, color = None, x_name = "x", y_name = "y"):
"""Plot a line from slope and intercept"""
axes = plt.gca()
x_vals = np.array(axes.get_xlim())
y_vals = intercept + slope * x_vals
plt.plot(
x_vals, y_vals, '--', color = color,
label = f"${y_name} = {slope:.2f}{x_name} " + ("-" if intercept < 0 else "+") + f"{abs(intercept):.2f}$"
)
# an extra function for plotting a straight line
def plot_abline(slope, intercept, color = None, x_name = "x", y_name = "y"):
"""Plot a line from slope and intercept"""
axes = plt.gca()
x_vals = np.array(axes.get_xlim())
y_vals = intercept + slope * x_vals
plt.plot(
x_vals, y_vals, '--', color = color,
label = f"${y_name} = {slope:.2f}{x_name} " + ("-" if intercept < 0 else "+") + f"{abs(intercept):.2f}$"
)
15.6. JNB LAB: Complex Systems#
15.6.1. Bifurcations in the Rozenzweig-MacArthur Predator Prey (RMPP) Equations#
In this section will look at Rozenzweig-MacArthur Predator-Prey (RMPP) Equations
(For background, see https://staff.fnwi.uva.nl/a.m.deroos/projects/QuantitativeBiology/43-HopfPoint-Rosenzweig.html)
Defining the equations RMPP is a 2D nonlinear system of ODEs
where:
\(F=\) prey density (eg rabbits)
\(C=\) predator density (eg foxes)
\(\frac{dF}{dt}\) = dynamic change of prey
\(\frac{dC}{dt}\) = dynamic change of predator
\(r\) = prey natural growth rate
\(K\) = prey carrying capacity
\(a\) = attack rate
\(h\) = handling rate (predator needs h time units to consume prey)
\(e\) = prey offspring proportionality constant to \(F\)
\(\mu\) - predator death rate
The following cell simulates the solution to RMPP over the time interval \(0\le t\le 500\) with parameter values \(r=.5,K=.05, a=5, h=3, e=.5, \mu=.1\)
Show code cell source
# timestep determines the accuracy of the euler method of integration
timestep = 0.001
# amplitude of noise term
amp = 0.
# the time at which the simulation ends
end_time = 500
# creates a time vector from 0 to end_time, separated by a timestep
t = np.arange(0,end_time,timestep)
# initialize rabbits (x) and foxes (y) vectors
x = []
y = []
"""" parameters"""
K=.05
r = .5
a=5
h=3
e=.5
m=.1
""" euler integration """
# initial conditions for the rabbit (x) and fox (y) populations at time=0
x0=.2
y0=.2
x.append(x0)
y.append(y0)
# forward euler method of integration
# a perturbbation term is added to the differentials to make the simulation stochastic
for index in range(1,len(t)):
# evaluate the current differentials
xd = r*x[index-1]*(1-x[index-1]/K) - a * x[index-1]*y[index-1]/(1+a*h*x[index-1])
yd = e*a*x[index-1]*y[index-1]/(1+a*h*x[index-1])-m*y[index-1]
# evaluate the next value of x and y using differentials
next_x = x[index-1] + xd * timestep
next_y = y[index-1] + yd * timestep
x.append(next_x)
y.append(next_y)
""" visualization """
if amp == 0:
# visualization of deterministic populations against time
plt.figure(figsize=(2,1))
plt.plot(x, y)
plt.text(x0,y0,'o',ha='center', va='center',color='r')
plt.text(x0,y0,' Initial Point',ha='left', va='center',color='r')
plt.ylabel('Predator Density')
plt.xlabel('Prey Density')
plt.title('Predator-Prey K='+str(K))
plt.show()
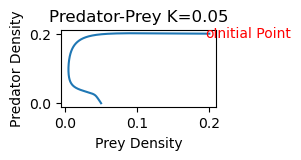
Note that the predators grow extinct and the prey density approaches a value of approximately .05.
References: https://staff.fnwi.uva.nl/a.m.deroos/projects/QuantitativeBiology/43-HopfPoint-Rosenzweig.html
Anthony Hills, https://github.com/INASIC/predator-prey_systems/blob/master/Modelling Predator-Prey Systems in Python.ipynb
Exercises#
Exercises
1 a) Define a function rmpp(x0,y0,K) which whose inputs specify the initial point (x0,y0) and prey carrying capacity K and whose output is a graph of the solution to the RMPP equations for \(0\le t \le 500\).
b) Check that your output for rmpp(.2,.2,.05) agrees with the above plot.
a) Make a chart showing the solution behavior as K is increased to .15, .25 and .3. (Note: for k=.3, also check the solution behavior for (x0,y0)=(.1,.15)) b) Describe the difference in the solution behavior for these K values.
Explain why RMPP has a Hopf bifurcation (one in which there is a critical value at which a stable equilibrium becomes unstable and a stable periodic solution is created.)
15.6.2. Sensitive Dependence on Initial Conditions in a Fitzhugh Nagumo System#
Imagine you are a new grad student. You are interested in applied math so are taking a course in ordinary differential equations (ODEs). One day, your professor talks about his colleague Dr. John Rinzel, who at the time was head of the math research branch at NIH (National Institutes of Health). Dr. Rinzel is an expert in mathematical neurobiology, and has developed several models of how neurons fire (active phase) and then relax (interval of quiescence). One of the nonlinear models he investigated is a 3 dimensional ODE system which we will refer to as the Fizhugh-Nagumo system (FHN):
\(v(t)\) is a membrane voltage variable which spikes when the neuron fires. \(w(t)\) represents the activity of several membrane channel proteins which help facilitate the neuron’s firing. The parameter I is a bifurcation parameter corresponding to the magnitude of the stimulus current. The underlying 2D system (without the variable \(y\)) undergoes a Hopf bifurcation. For \(I<I_{crit}\), there is a stable spiral equilibrium point which corresponds to the interval of quiescence. For \(I<I_{crit}\), the equilibrium point loses its stability as there is a stable periodic solution which corresponds to the spiking of \(v\) during the active phase.
Note that in the 3D system, if I is fixed, the inclusion of y(t) will effectively move the 2D system back and forth across the bifurcation point of the 2D system.
Using parameter values and initial point specified by Dr. Rinzel, we solve the FHN system numerically and plot the solution to to see the action potentials.
Show code cell source
def solve_FHN(x0,N=10, max_time=1000.0, I=.3125, phi=.08, theta=.0006,a=.7,b=.8,c=-.775,d=1):
def FHN_deriv(v_w_y,t0=0, x0=x0,phi=phi, theta=theta, I=I,a=a,b=b,c=c,d=d):
"""Compute the time-derivative of a FHN system."""
v, w, y = v_w_y
return [v-v**3/3-w+y+I, phi*(v+a-b*w),theta*(-v+c-d*y) ]
# Solve for the trajectories
t = np.linspace(0, max_time, int(250*max_time))
x_t = integrate.odeint(FHN_deriv, x0, t)
return t, x_t
[t,x_t]=solve_FHN([1.744,.298,.00872]) # Initial conditions v=1, w=0, y=0.
plt.plot(t,x_t)
plt.legend(["v(t)","w(t)","y(t)"])
plt.savefig("FHN1.png")
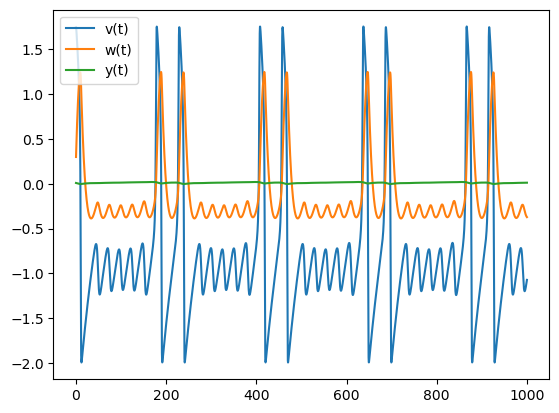
The periodic oscillation for v(t) has a stable burst pattern denoted 1100000 meaning that two large spikes (11) followed by five small oscilations (ooooo); this pattern will recur over and over.
Exercise#
Exercise
Explain how the bursting behavior in FHN is related to a Hopf bifurcation in the underlying 2D system.
Nonlinear ODE systems can exhibit complex behavior such as sensitive dependence on initial conditions.
a) Re-simulate FHN using the same paramter values and the initial condition x0=[1.725,.337,.00764]. What do you observe? b) Why does FHN exhibit sensitive dependence on initial conditions and how does FHN exhibit this?
15.6.3. Random Walks#
A random walk beginning at \(x_0=0\), is such that \(x_t\), the position at timestep \(t=0,1,2,...\) is
where \(e_t=\pm 1\) with equal probability. The random variables \(e_t\) and \(e_{t'}\) (\(t\neq t')\) are assumed to be independent and identically distributed (IID).
The following cell simulates a random walk.
Show code cell source
x=[0]
t=[0]
for i in np.arange(1,1000,1):
x.append(x[i-1]+random.choice((-1, 1)))
t.append(i)
plt.plot(t,x)
Although each individual random walk is completely unpredictable, a large ensemble of random walks has a predictable structure since
Show code cell source
x=[0]
t=[0]
xf=[]
xf2=[]
for run in np.arange(0,1000):
for i in np.arange(1,5000,1):
x.append(x[i-1]+random.choice((-1, 1)))
t.append(i)
xf.append(x[4999])
xf2.append(x[4999]**2)
plt.plot(t,x)
x=[0]
t=[0]
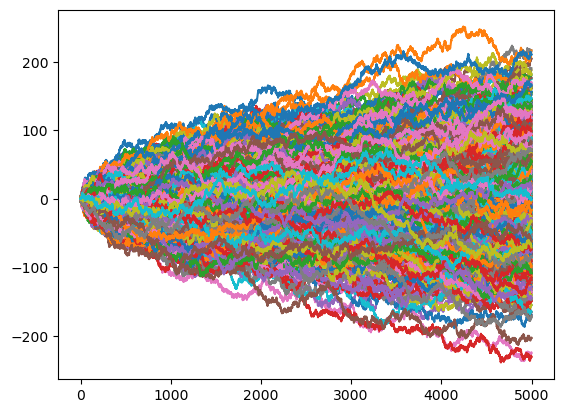
Note that after 5000 steps, the mean for 1000 random walks of \(x_t\) (t=4999) is close to 0, and the mean of \(x_t^2\) is close to t. In other words, for a normal random walk with \(x_t=0\), the mean is zero (\(<x_t>=0\)) and the variance grows linearly with \(t\) (\(<x_t^2>=t\)):
Show code cell source
print("Mean of x[4999]=", np.mean(xf))
print("Mean of x[4999]^2=", np.mean(xf2))
Mean of x[4999]= 0.566
Mean of x[4999]^2= 5195.856
Here is a graph of a 2D random walk with 1000 steps (both the x position and y position are random walks.)
Show code cell source
# Set seed for reproducible results (optional)
np.random.seed(10)
# Initial particle position
current_xpos = 0
current_ypos = 0
# Initial list of positions
x = [current_xpos]
y = [current_ypos]
# Define number of particle steps
N = 1000
# Generate set of random steps in advance (it could also be done inside the for loop)
xstep = np.random.randint(-1,2,N)
ystep = np.random.randint(-1,2,N)
# Iterate and track the particle over each step
for i in range(N):
# Update position
current_xpos += xstep[i]
current_ypos += ystep[i]
# Append new position
x.append(current_xpos)
y.append(current_ypos)
# Plot random walk
plt.figure(figsize=(10,5))
plt.plot(x, y)
plt.show()
Brownian Motion
We can also create a random walk using variable step sizes by drawing from a standard normal distribution (np.random.normal(0, 1, 1000))
Show code cell source
# Set seed for reproducible results (optional)
np.random.seed(10)
# Initial particle position
current_xpos = 0
current_ypos = 0
# Initial list of positions
x = [current_xpos]
y = [current_ypos]
# Define number of particle steps
N = 1000
# Generate set of random steps in advance (it could also be done inside the for loop)
xstep = np.random.normal(0,1,N)
ystep = np.random.normal(0,1,N)
# Iterate and track the particle over each step
for i in range(N):
# Update position
current_xpos += xstep[i]
current_ypos += ystep[i]
# Append new position
x.append(current_xpos)
y.append(current_ypos)
# Plot random walk
plt.figure(figsize=(10,5))
plt.plot(x, y)
plt.show()
Exercise#
Exercise
a) A standard Cauchy distribution with p.d.f. \(f(x)=\frac{1}{\pi(1+x^2)}\) is a heavy tail distribution with \(<x>=0\) and infinite variance. Simulate a 2D random walk with \(N=1000\) steps where each step is determined by a random draw from a Cauchy distribution (np.random.standard_cauchy(N)).
b) What difference do you notice about this random walk compared with brownian motion.
a) Plot the probability density function of a standard Cauchy distribution and a standard normal distribution. Explain why the former is said to have a heavy tail.
b) What is the significance of ‘long flights’ in Cauchy random walks?
15.6.4. Scale Adjusted Metropolitan Index (SAMI)#
Urban scaling theory conceptualizes cities as interdependent socioeconomic and spatial (infrastructural) networks that coevolve to support each other. Major goals include:
Find empirical characteristics of cities as a whole (extensive properties) such as GDP or road surface area which exhibit scale invariant relations (vary on average with city size).
develop an urban scaling theory to explain the observed patterns
develop predictive models
An extensive property of cities has the form
\(i=1,...,N_c\) correspond to cities
\(N_i\) is a measure of system size varies continuously with time \(t\)
\(Y_0(t)\) is a prefactor independent of scale
\(\beta\) is a scaling exponent (elasticity) expressing the average relative percentage change in \(Y\) given a percentage variation in \(N\) at a fixed time \(t\).
\(\xi_i(t)\) are residuals which account for deviations of city \(i\) from the average scaling pattern of all cities. The residuals satisfy
Scaling laws arise when the variance \(\sigma^2=\frac{1}{N_c}\sum_{i=1}^{N_c} \xi_i^2\) is scale independent.
Scaling laws
A socio-economic variable (\(Y\)) follows a population (\(N\)) scaling law if
with \(G>0\) and \(\beta\) are constants independent of the value of \(N\).
Example
GDP of cities in China.
chinagdp = pd.read_excel('chinaGDP.xlsx')
chinagdp.head()
| City | Pop | GDP | |
|---|---|---|---|
| 0 | Shanghai | 26875500 | 664 |
| 1 | Beijing | 21167303 | 619 |
| 2 | Shenzhen | 17633800 | 482 |
| 3 | Chongqing | 12313714 | 433 |
| 4 | Guangzhou | 18810600 | 429 |
for i in chinagdp.index:
chinagdp.loc[i,"LnPop"]=np.log( chinagdp.loc[i,"Pop"])
chinagdp.loc[i,"LnGDP"]=np.log( chinagdp.loc[i,"GDP"])
chinagdp.shape
(29, 5)
sns.lmplot(
data = chinagdp,
x = 'LnPop',
y = 'LnGDP',
ci = None
);
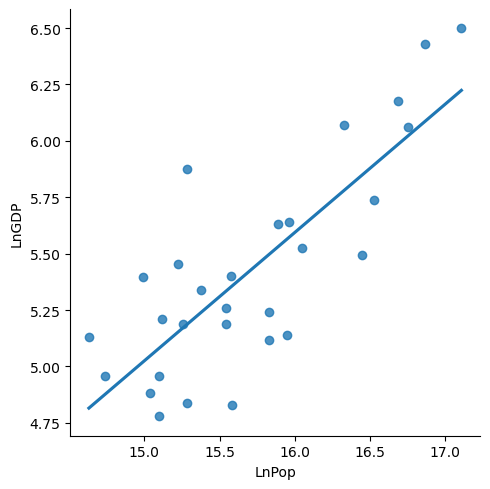
x = 'LnPop'
y = 'LnGDP'
lin_mod = sm.regression.linear_model.OLS(
chinagdp[y], # the dependent variable (y)
sm.tools.tools.add_constant(chinagdp[x]) # the independent variable (x)
)
results = lin_mod.fit()
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: LnGDP R-squared: 0.638
Model: OLS Adj. R-squared: 0.624
Method: Least Squares F-statistic: 47.51
Date: Fri, 29 Dec 2023 Prob (F-statistic): 2.09e-07
Time: 11:03:43 Log-Likelihood: -4.2813
No. Observations: 29 AIC: 12.56
Df Residuals: 27 BIC: 15.30
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -3.5082 1.298 -2.703 0.012 -6.171 -0.846
LnPop 0.5689 0.083 6.893 0.000 0.400 0.738
==============================================================================
Omnibus: 0.209 Durbin-Watson: 1.699
Prob(Omnibus): 0.901 Jarque-Bera (JB): 0.324
Skew: 0.176 Prob(JB): 0.850
Kurtosis: 2.620 Cond. No. 380.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Note that the data for China has 𝛽=.5689.
Show code cell source
fig, axes = plt.subplots(1,1, sharex = True, sharey = True, figsize = (10,7))
slopes = [.5689]
intercepts = [-3.5082]
(scattercolor, trendcolor, residcolor) = sns.color_palette()[0:3]
# plot data
sns.scatterplot(
data = chinagdp,
x = 'LnPop',
y = 'LnGDP',
color = scattercolor,
)
# plot the line with given slope and intercept
plot_abline(slopes[0], intercepts[0], color = trendcolor)
# plot residuals
for j, (x, y) in enumerate(zip(chinagdp['LnPop'], chinagdp['LnGDP'])):
plt.plot(
[x, x], [y, slopes[0]*x + intercepts[0]],
color = residcolor, alpha = 0.5,
label = "residuals" if j == 0 else "" # show legend entry only for first residual in each plot
)
for j, (x, y) in enumerate(zip(chinagdp['LnPop'], chinagdp['LnGDP'])):
plt.text(x,y,chinagdp.loc[j,"City"])
plt.text(x,y-.05,str(np.round(y-(slopes[0]*x + intercepts[0]),2)))
plt.legend(loc = "upper left")
plt.savefig("ChinaSAMI.png")
plt.gca().set_title(f"SAMI with Trend Line")
Text(0.5, 1.0, 'SAMI with Trend Line')
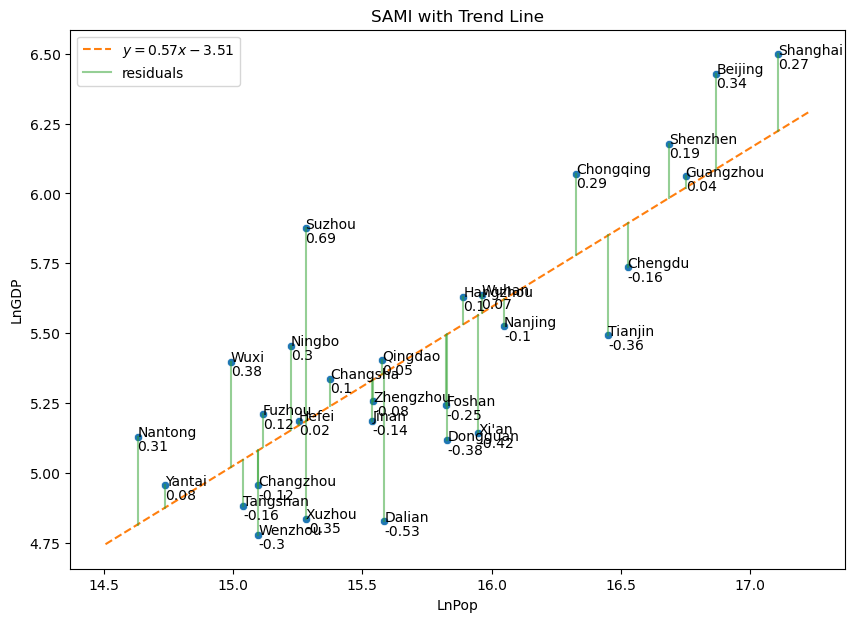
Exercise#
Exercise
Where would Hong Kong fall if added to the SAMI graph above?
15.6.5. Internally Displaced People (IDP) in Tigray, Ethiopia#
A peace agreement was signed in Pretoria, South Africa in November 2022, two years after a horrific war broke out in Tigray, the northernmost region of Ethiopia. An estimated four hundreds thousand Tigrayan civilians were killed out of a population of 6 or 7 million, and a hundred thousand women were raped. The entire region was traumatized. Thousands of schools were damaged/closed and millions of children were out of school for over two years. The vast majority of medical facilities were rendered inoperative. Young people in large number escaping reality through drugs and alcohol additions.
One year after the peace agreement, fighting continued in western Tigray and 1 million internally displaced people (IDP) were living in over 600 IDP camps scattered across Tigray. Most camps are have sub-standard living conditions–acute food and clean water shortages; many living in severely overcrowded rooms in damaged schools or in tents; no livelihood, nothing to return to even if peace is established back home.
In this lab, we look at IDP camp data collected in summer 2023. The data set is large (638 rows or camp observations and 468 columns or attributes) so we begin with exploratory data analysis to get a feel for the data as a whole. Our goal then shifts to addressing the question of how an NGO concerned with the plight of IDPs might prioritize their efforts based on i) areas within Tigray that are underserved and ii) ranking of the severity of the need of individual camps within underserved regions.
The IDP data we analyzed was obtained at https://data.humdata.org/dataset/ethiopia-displacement-northern-region-tigray-idps-site-assessment-iom-dtm?
Let’s put the IDP data into a dataframe called “df”.
df = pd.read_excel("IDP.xlsx")
df.head(1)
| 1.1.a.1: Survey Date | Country | Country Code | Reported Date | 1.1.a.2: Survey Round | 1.1.c.1: Site ID | 1.1.d.1: Site Name | 1.1.d.2: Site Alternate Name | 1.4.a.2: Is site open? | 1.1.e.1: Region | ... | S1723: Other internet sources (e.g. apps) | S1723: Please specify which other internet sources | S1723: Other | S1723: If other source of news/information, please specify | S1784: Is mobile network access available in the site? | S1495: What % of HHs own a mobile phone? | 11.3.a.1: Are members of the community discussing/advertising travel opportunities? | 11.3.a.6: If Yes, to where? | 11.3.a.2: Specify all locations | M1712: Additional Comments / Observations | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | #date+occurred | #country+name | #country+code | #date+reported | NaN | NaN | NaN | NaN | NaN | #adm1+name | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
1 rows × 488 columns
Select columns to assess disorder.
Show code cell source
#Pre-primary, secondary, resources,
#quality/satisfaction, girl attendance, boy attendance, teachers
columns_to_keep = ['1.1.d.1: Site Name',
'1.1.e.2: Zone',
'1.1.e.3: Woreda',
'1.1.f.1: GPS: Longitude',
'1.1.f.2: GPS: Latitude',
'2.1.b.7: Total Number of IDP Individuals',
'M1594: What is the severity of site/area overcrowding',
'1.2.a.1: Is there any registration activity?',
'What are the biggest priority need(s) for IDPs in this site?/Food',
'What are the biggest priority need(s) for IDPs in this site?/Shelter',
'What are the biggest priority need(s) for IDPs in this site?/WASH',
'What are the biggest priority need(s) for IDPs in this site?/Livelihoods',
'What are the biggest priority need(s) for IDPs in this site?/Healthcare',
'What are the biggest priority need(s) for IDPs in this site?/Protection services',
'S1225: Are IDPs satisfied with the standard of schools for children in their location',
]
data = df[columns_to_keep]
new_column_names = ['Name','Zone','Woreda','Long','Lat','Pop','Crowded','Registration','Food','Shelter','WASH','Livelihood','Healthcare','Protection','Education']
data.columns = new_column_names
data=data.dropna()
data.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Hareze Seb'ata | Eastern | Erob | 39.5828 | 14.43946 | 10410 | High | Yes, but the list is incomplete | No | Yes | Yes | Yes | No | No | No |
data.shape
(642, 15)
Binary code deficiencies (1=deficient)
Show code cell source
# Assuming 'data' is your DataFrame with qualitative columns
# Define mapping functions for each column
def map_crowded(value):
return 1 if 'High' in value else 0
def map_registration(value):
return 1 if 'No' in value else 0
def map_food(value):
return 1 if 'Yes' in value else 0
def map_shelter(value):
return 1 if 'Yes' in value else 0
def map_wash(value):
return 1 if 'Yes' in value else 0
def map_livelihood(value):
return 1 if 'Yes' in value else 0
def map_healthcare(value):
return 1 if 'Yes' in value else 0
def map_protection(value):
return 1 if 'Yes' in value else 0
def map_education(value):
return 1 if 'No' in value else 0
# Apply the mapping functions to each column
data['Crowded'] = data['Crowded'].apply(map_crowded)
data['Registration'] = data['Registration'].apply(map_registration)
data['Food'] = data['Food'].apply(map_food)
data['Shelter'] = data['Shelter'].apply(map_shelter)
data['WASH'] = data['WASH'].apply(map_wash)
data['Livelihood'] = data['Livelihood'].apply(map_livelihood)
data['Healthcare'] = data['Healthcare'].apply(map_healthcare)
data['Protection'] = data['Protection'].apply(map_protection)
data['Education'] = data['Education'].apply(map_education)
# Display the updated DataFrame
data.head()
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Hareze Seb'ata | Eastern | Erob | 39.58280 | 14.43946 | 10410 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
| 2 | Enda Mosa | Eastern | Erob | 39.55493 | 14.42384 | 10230 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 3 | Adi Abagie | North Western | Adi Daero | 38.18660 | 14.26590 | 196 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | May Ambssa | North Western | Adi Daero | 38.23350 | 14.22740 | 117 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 5 | Hibret | North Western | Adi Daero | 38.16930 | 14.32020 | 242 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
Find the total number of needs in each camp and the total number of IDP in camps with i needs.
for i in data.index:
data.loc[i,"sum"]=int(data.loc[i,'Crowded']+data.loc[i,'Registration']+data.loc[i,'Food']+data.loc[i,'Shelter']+data.loc[i,'WASH']+data.loc[i,'Livelihood']+data.loc[i,'Healthcare']+data.loc[i,'Protection']+data.loc[i,'Education'])
data.head(3)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Hareze Seb'ata | Eastern | Erob | 39.58280 | 14.43946 | 10410 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 5.0 |
| 2 | Enda Mosa | Eastern | Erob | 39.55493 | 14.42384 | 10230 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 5.0 |
| 3 | Adi Abagie | North Western | Adi Daero | 38.18660 | 14.26590 | 196 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 3.0 |
Show code cell source
def population(data):
pop=[0,0,0,0,0,0,0,0,0,0]
for i in data.index:
if data.loc[i,"sum"]==0:
pop[0]=pop[0]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==1:
pop[1]=pop[1]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==2:
pop[2]=pop[2]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==3:
pop[3]=pop[3]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==4:
pop[4]=pop[4]++data.loc[i,"Pop"]
if data.loc[i,"sum"]==5:
pop[5]=pop[5]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==6:
pop[6]=pop[6]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==7:
pop[7]=pop[7]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==8:
pop[8]=pop[8]+data.loc[i,"Pop"]
if data.loc[i,"sum"]==9:
pop[9]=pop[9]++data.loc[i,"Pop"]
return pop
totalpop=population(data)
np.sum(totalpop)
1021593
Create dataframes with data for each of the 6 zones.
data["Zone"].value_counts()
Central 191
North Western 140
Eastern 130
South East 73
Mekelle 55
Southern 53
Name: Zone, dtype: int64
tot=642 #total number of camps
U=data["sum"].sum()/tot
U #mean number of needs
3.1183800623052957
central_df = data[data['Zone'] == 'Central']
centralpop=needlevel(central_df)
central_df.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9 | Kewanit | Central | Tahtay Maychew | 38.634 | 14.0922 | 136 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 4.0 |
centralpop
[0, 185, 66443, 98460, 34418, 24262, 0, 0, 0, 0]
NW_df = data[data['Zone'] == 'North Western']
NWpop=needlevel(NW_df)
NW_df.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | Adi Abagie | North Western | Adi Daero | 38.1866 | 14.2659 | 196 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 3.0 |
NWpop
[0, 5917, 84960, 105586, 78965, 34967, 5242, 0, 0, 0]
eastern_df = data[data['Zone'] == 'Eastern']
easternpop=needlevel(eastern_df)
eastern_df.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Hareze Seb'ata | Eastern | Erob | 39.5828 | 14.43946 | 10410 | 1 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 | 5.0 |
easternpop
[0, 702, 44725, 47223, 14953, 24134, 23113, 0, 0, 0]
# Filter rows with 'Mekele' in the 'City' column
SE_df = data[data['Zone'] == 'South East']
SEpop=needlevel(SE_df)
SE_df.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 263 | Adi-Keyh | South East | Wejerat | 39.667 | 13.0126 | 326 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 2.0 |
SEpop
[0, 469, 11772, 9957, 12005, 0, 0, 0, 0, 0]
mekelle_df = data[data['Zone'] == 'Mekelle']
mekellepop=needlevel(mekelle_df)
mekelle_df.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 559 | Hayelom Elementary School | Mekelle | Hawelti Sub City | 39.45346 | 13.50069 | 1760 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 3.0 |
mekellepop
[0, 14009, 79426, 78206, 29365, 33478, 0, 0, 0, 0]
southern_df = data[data['Zone'] == 'Southern']
southernpop=needlevel(southern_df)
southern_df.head(1)
| Name | Zone | Woreda | Long | Lat | Pop | Crowded | Registration | Food | Shelter | WASH | Livelihood | Healthcare | Protection | Education | sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 295 | Ebo | Southern | Raya Azebo | 39.6911 | 12.8469 | 123 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 4.0 |
southernpop
[0, 0, 3203, 10645, 33313, 11490, 0, 0, 0, 0]
15.6.6. Exercises#
Exercises
Compute the mean, weighted mean, entropy, and weighted entropy for each of the 6 zones.
Make a histogram for each zone which shows the number of IDP living in camps with i deficiencies (i=0,1,2,3,4,5,6,7,8,9).